I have a little problem. Well, maybe it’s a big problem. I need a backup of the /home2/art directory on my computer. All told, it contains about 19,000 photos, a few full length movies, the video from my wedding, and some audio. It weights in at 227 GB. My /home/art directory has another 17,000 photos but, since it is “only” 91 GB, it already has a good backup. Last week, I found a solution. To make a backup, I type this at the command line and then I wait:
aws s3 sync /home2/art s3://bd4c/home2/ --delete
And if I ever need to restore the directory, I will type this:
aws s3 sync s3://bd4c/home2/ /home2/art
Read on to learn how to do this yourself. It works on Windows, Mac, and Linux.
Requirements
To arrive at that backup solution, I started with a few requirements:
- It has to run on Linux.
- Backups have to easy and scriptable. I want to schedule (or manually run) a simple command and have the backups “just happen.” If something goes wrong (like a power failure or an internet glitch), I want to just run the command again and everything should magically heal itself.
- Restorations have to be super easy. Whether I want a single file or a directory of files or all of my files restored, I want to just run a simple command and get my files back. As with the backups, if something goes wrong, I want to just rerun the command and the problem should vanish.
- It has to be reliable. Once I set the system up, I want to be absolutely certain that my files will be there if (when) I need them.
- It has to be cheap.
There are a few things which I do not need, and this simplifies the issue.
- I do not need point-in-time recovery. I.e., I will never want to restore things “as they were 10 days ago.” I just want an archival copy of my pictures. I add things. I don’t delete them.
- I do not have a preconceived notion of where the backups get stored. I do not care whether they are near me or “in the cloud.”
- I do not care whether a restore takes a long time, even several days.
Amazon Web Services (AWS) has two services which, combined, do everything that I need.
Amazon Glacier provides highly reliable, long term file storage for a measly $0.004 per GB. “It is designed to provide average annual durability of 99.999999999%” for each file. Those seem like pretty good odds to me.
Amazon Simple Storage Service (S3) has a command line program which will let me back up and restore files with a trivial amount of effort. It also lets me define “lifecycle rules” which will automatically move the files from the relatively expensive S3 standard storage class ($0.023 per GB) to the much less expensive Glacier storage class ($0.004 per GB).
Overview
Here are the steps we will follow:
- Create the S3 bucket
- Create the lifecycle rule
- Create the AWS IAM user
- Install the AWS command line interface tools
- Create the backup
Steps 1-4 only need to be done once.
1) Create the S3 Bucket
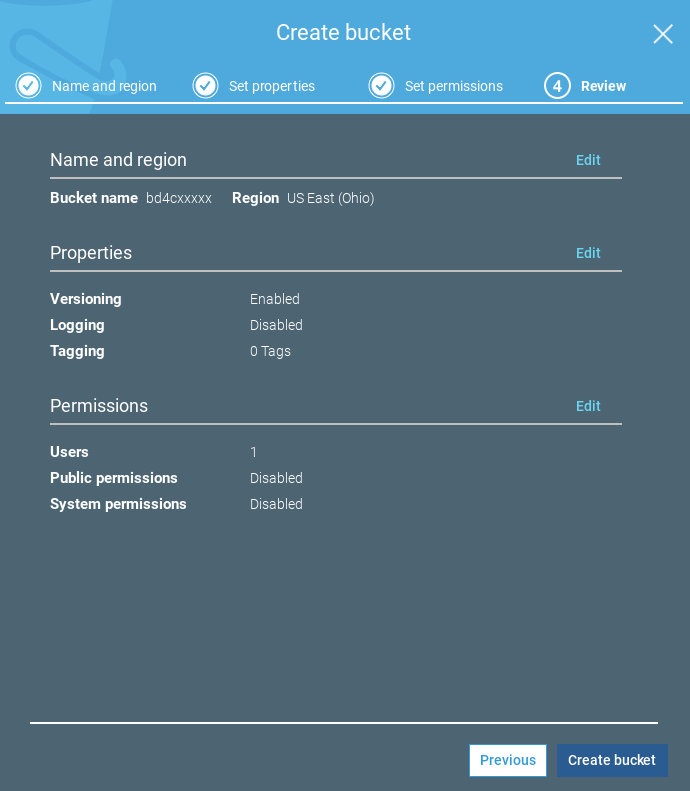
Using the AWS Console, I started by creating an Amazon S3 bucket named “bd4c,” because my desktop computer is named “bd4c.” (I know… too clever.) I selected the US East (Ohio) region for its low price. I enabled versioning, so that deleted files can still be recovered, even though I almost never delete files from these directories. (You can click on any of these screen snapshot to see versions that are large enough to read.)
2) Create the Lifecycle Rule
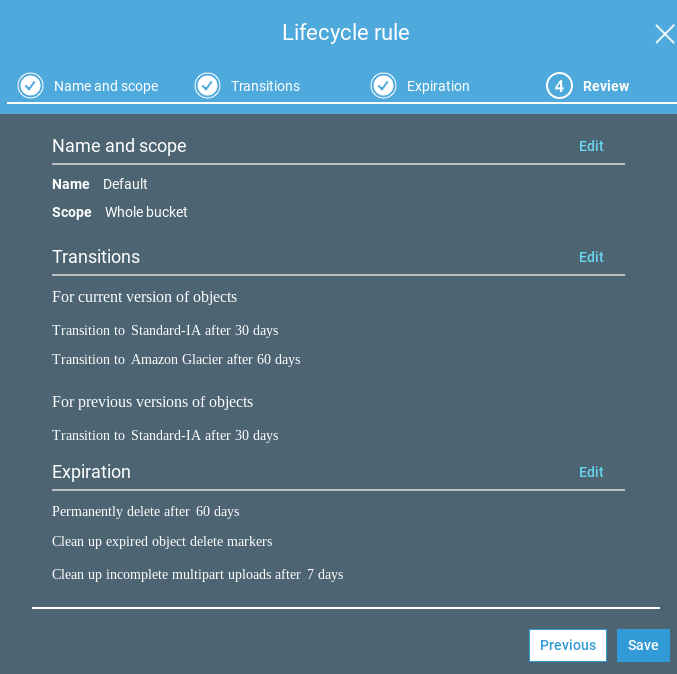
Still using the AWS Console, I created a lifecycle rule to reduce costs of the backups, by automatically switching the files to the least expensive storage class. This was as easy as clicking Management -> Lifecycle -> “Add lifecycle rule” and selecting these options:
- Newly uploaded files have the Standard storage class which costs $0.023 per GB.
- 30 days after a file is uploaded, it’s storage class gets changed from Standard to Standard Infrequent Access (Standard-IA). This drops the price to $0.0125 per GB. It adds the constraint that I will pay for 30 days of storage for each file, even if I delete it sooner, but that is OK because this is archival storage.
- 90 days after a file is uploaded, it’s storage class gets changed from Standard Infrequent Access to Glacier. This drops the price to a miserly $0.004 per GB. Glacier adds three constraints:
- The files are not always accessible. To download a file, I first have to initiate a restore. This typically takes 3-5 hours, though it can be expedited if I pay a higher fee.
- The minimum storage time is 90 days. If I delete a file sooner, I still pay for 90 days.
- The minimum storage size is 128 KB. Since I am backing up big files (photos and videos), this will not affect me.
- After 90 days, the lifecycle rule deletes previous versions of files. It does not move them to Glacier.
3) Create an AWS IAM User
I used the AWS Console to create an IAM user that has access restricted to S3. After creating the user, I noted the access key and the secret access key.
4) Install the AWS Command Line Interface (AWS CLI)
I run Ubuntu Linux on my computer so there are two easy ways to install the AWS command line utilities. I can get them from the official Ubuntu repositories with sudo aptitude install awscli or I can get them from the Python repositories with sudo pip install awscli. I chose PIP because it gets updated more frequently than the Ubuntu version.
I ran aws configure and entered the access keys. I also set the default region to us-east-2 , the US East (Ohio) region which I mentioned earlier.
5) Create a Backup
Now I can create a backup by running this command
aws s3 sync /home2/art s3://bd4c/home2/ --delete
The synchronized my local directory with the S3 bucket, deleting any remote files which no longer exist on the local disk.
Here is the result, after several days of uploading:
$ aws s3 ls s3://bd4c/home2 --recursive --human-readable --summarize | tail -2 Total Objects: 54974 Total Size: 226.4 GiB
Costs
Costs are cheap. For my 227 GB, I will pay approximately
- $5.25 for month 1
- $2.85 per month for months 2 and 3
- $0.91 per month thereafter
Should I ever need to restore some files, I check to see if the files are in Glacier. If they are, I use the AWS Console to initiate a restore and wait for that operation to complete. It does incur a cost of $0.01 per GB and takes 3-5 hours but, if I am in a hurry, I can request an expedited restore for $0.03 per GB; that will complete in 5 minutes. Once the S3 restore is done, I can run aws s3 sync to copy the files from S3 back to my computer.
I will also pay to transfer the data out of S3, should I ever need to restore it. Current price is $0.09 per GB, or $20.43 for the entire 227 GB. If I never do a restore then I never incur this cost.
Conclusion
This achieved all of my goals. The aws s3 sync command is reliable and restartable. With the –delete option, it makes the S3 bucket look almost exactly like my local files. (S3 does not store empty directories.) It is smart enough to only transfer files which are different, saving time.
